Sto cercando di risolvere il nuovo problema ois_lava.
Bisogna trovare il percorso minimo in una griglia con degli ostacoli, questo mi aveva fatto pensare all’A* search o comunque al dijkstra.
L’algoritmo che ho usato è questo, usa una coda per sapere quali nodi deve visitare:
Aggiungi 0,0
Finché ci sono nodi nella lista
– Aggiungi tutti i nodi intorno a cui ci si può spostare
– Aumenta il numero di passi
– Muovito verso il più vicino alla fine
Il problema è che se il percorso che segue inizialmente non è ottimale, il numero di passi non diminuisce e stavo pensando a un modo per far questo.
Non dovrebbe essere così. Tutto dipende dalla funzione euristica h(x), o meglio dalla sua ammissibilità. Per essere ammissibile, \forall x, h(x) \leq dist(x, dest) ,e ciò che hai fatto tu, ovvero la distanza di Manhattan lo è.
Piuttosto, c’è un punto che è sbagliato nel tuo algoritmo, ma non ha niente a che vedere con l’euristica. Ovvero, che devi memorizzare nella coda gli stati come coppia ( P, dist(S, P) + h(P)) e ordinarli in base al secondo valore. In questo modo, consideri pure quando, incontrando un ostacolo, inizi a “girare in torno troppo a lungo”. (riga 52 su pastebin)
La soluzione più semplice è una bfs, dato che il grafo non è pesato il percorso che passa per meno archi è anche il più veloce, quindi una casella è aggiunta alla coda una sola volta, così la complessità resta bassa.
È vero, è più semplice una bfs in questo caso. Comunque, volevo provare un po’ a farla, dato che non l’ho mai usata prima
Ultima nota per quanto riguarda A*: la distanza di Manhattan va corredata di calcolo della diagonale. Usare la distanza euclidea in generale è giusto ma in questo caso per migliorare l’euristica ed evitare valori decimali ti consiglio di fare la funzione distanza migliorando abs(X - M + 1 - Y - N + 1) per considerare pure le diagonali.
ciao,
io ho risolto il problema con la BFS ma… per un pelo! Infatti l’ultima istanza del subtask 3 viene calcolata in esattamente 1 sec!
E per riuscire a non sforare il limite ho dovuto anche combattere con l’I/O (vedi nota sotto)
Vedo invece nelle statistiche soluzioni molto più efficienti. Dov’è il problema della mia soluzione? ci sono 3 possibilità
le soluzioni più efficienti usano un algoritmo diverso
la mia BFS è inefficiente per qualche motivo (mi pare strano l’ho sempre fatta allo stesso modo)
costruisco un grafo più grande del necessario. Ho provato a pensarci, ma a me sembra che devo mettere un nodo per ogni casella e un’arco tra ogni coppia di caselle tra cui è consentito fare i salti. Forse posso risparmiare alcuni archi?
Nota sull’I/O (leggi William )
A mio avviso, il template di soluzione proposto non è corretto nel leggere le righe della matrice di caratteri. Il template legge con fscan usando “%s” una riga di caratteri alla volta, memorizzandoli in un buffer di W char. Il problema è che fscanf, quando si usa “%s”, aggiunge automaticamente un carattere nullo che termina la stringa, e quindi scrive nel buffer W+1 caratteri (si veda sez. 7.19.6.2 dello standard C99, ad esempio). Invece il template alloca W caratteri per ciascuna riga.
Io, proprio per evitare lo spreco di memoria causato dalla necessità di allocare 1 char in pìu per ogni riga, volevo leggere uno alla volta i caratteri della matrice, ma così facendo la mia soluzione sfora il timelimit su l’istanza critica.
Mmm… probabilmente è questo, cioè, il tempo di costruzione del grafo può essere abbastanza alto (per esempio in una griglia in cui non c’è lava, il numero di nodi raggiunge 10^6 e il numero di archi circa 12 \cdot 10^6).
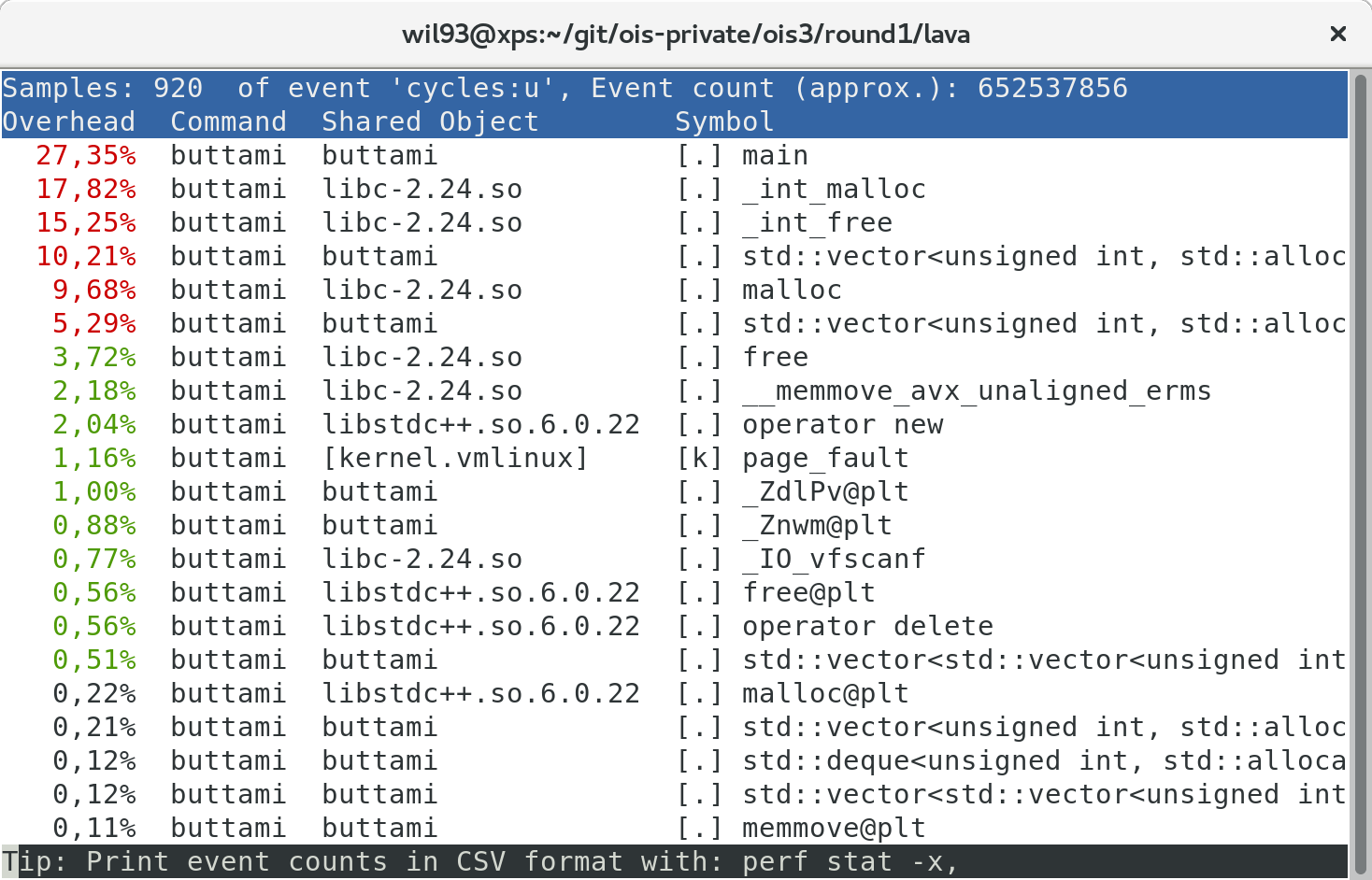
Ho provato a fare un profiling della soluzione, con i comandi:
perf record ./buttami < input.txt
perf report
(buttami = temporaneo ) e in effetti vedo che il maggior overhead sembra dovuto alla costruzione del grafo:
@Vash: certo non è la lettura che richiede 1 sec, ma nella mia implementazione fa la differenza tra impiegare 1.000 e 1.048 sec, ovvero tra i 100 punti e i 70!
@all: comunque mi convince il fatto che sia la costruzione esplicita del grafo il problema… proverò a farlo implicitamente. Grazie!
@wil93: occhio che il medesimo errore potrebbe essere in altri template, ad esempio Kabbalah
Mi sono appena accorto che l’errore era non solo anche in kabbalah, ma anche che la riga incriminata fa una cosa diversa da quella prevista . Usiamo sizeof(char*) invece di sizeof(char), ovvero 8 invece di 1. Questo evita sicuramente il problema che dicevi (andare a scrivere fuori dall’array) ma introduce un leggero spreco di memoria (non grave, ma sicuramente nemmeno ovvio, guardando il codice).
Quando il grafo può essere così denso, un overhead significativo viene introdotto dal solo uso ripetuto di vector.push_back, che può causare riallocazione.
In tal caso è utile indicare in anticipo quanti elementi si prevede che verranno inseriti nel vettore. Nel caso di esempio, l’aggiunta delle istruzioni:
for (int i = 0; i < N; i++)
graph[i].reserve(12);
prima di costruire il grafo ha ridotto di circa il 30% il tempo di esecuzione nel caso peggiore con grafo denso.
Ogni volta che salvi/leggi un nodo, invece di usare un intero usi due interi (le coordinate). E ogni volta che iteri sui vicini di un nodo dovrai calcolare manualmente i vicini, invece che scorrere una lista di adiacenza precalcolata.
Per calcolare i vicini, una buona idea è spesso quella di usare due array globali (di solito chiamati di e dj oppure dx e dy in modo tale che i + di[k] e j + dj[k] contengono le “nuove coordinate” per il k-esimo vicino). In questo specifico task, ci sono ogni volta al massimo 12 vicini possibili.