Ho qualche problemino su questo problema, (ci sono complessivamente da 6 ore, tra poco impazzisco) mi sembra di aver sviluppato una logica abbastanza solida, ma è probabile abbia sbagliato qualche cosa nell’implementazione solo che mi viene difficile capire cosa…
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ull = unsigned long long;
using vi = vector<int>;
#define pb push_back
#define all(x) begin(x), end(x)
#define sz(x) (int) (x).size()
#define endl "\n"
#define mod 1000000007
using pi = pair<int,int>;
#define mp make_pair
void fast() {
ios_base::sync_with_stdio(false); cin.tie(NULL); cout.tie(NULL);
}
vector<ll> dp;
struct cmp{ //comparatore per ordinare i nodi in base alla loro dp, chi ha la dp maggiore va prima
bool operator()(const int &a, const int &b) const {
if(dp[a] == dp[b]) return a < b;
return dp[a] > dp[b];
}
};
vector<set<int, cmp>> adj; // lista di adiacenza con i set ordinati in modo personalizzato
vector<ll> tempo; //tempo per risolvere la task[i]
vector<int> parent; //parent[i] contiene il padre del nodo i (-1 nel caso della radice)
int radice = 0;
pair<int, ll> cheat = {-1, LLONG_MAX}; //soluzione che contiene rispettivamente {nodo da eliminare, quanto riesce a risparmiare}
ll dfs(int node){ //dfs che inizializza la dp, simulando appunto C = 0, dove dp[i] sarebbe il tempo necessario per risolvere il sotto albero con radice i
ll sol = 0;
for(auto u : adj[node]){
ll dist = dfs(u);
sol = max(sol, dist);
dp[u] = dist;
}
return tempo[node] + sol;
}
ll individua(int node){ //funzione per individuare il nodo da eliminare, in breve scende attraverso le dp maggiori e quando risale simula di eliminare
//i nodi volta per volta capendo così quale nodo fa risparmiare di più
if(adj[node].empty()) { // se il nodo è una foglia
cheat.first = node; // attualmente è la nostra soluzione
int father = parent[node];
if(adj[father].size() == 1) return cheat.second = tempo[node]; // se non ha fratelli allora sappiamo che risparmia tempo[node]
int fratello = *next(adj[father].begin()); // prendiamo il fratello con la dp più alta
return cheat.second = min(tempo[node], dp[node] - dp[fratello]); // se risparmia troppo tempo e fa diventare dp[node] < dp[fratello] allora per
// il totale si utilizzerà il fratello più grande, quindi abbiamo risparmiato dp[node] - dp[fratello]
}
int figlio = *adj[node].begin(); // prendiamo il figlio con dp maggiore
ll guadagno = individua(figlio); // ricorsivamente arriviamo alla foglia per attivare il caso base
if(guadagno < tempo[node]) { // se il risparmio, che abbiamo ottenuto eliminando un nodo nel sottoalbero con radice figlio, è minore di quello che possiamo risparmiare eliminando il nodo attuale
// allora la nostra soluzione diventa questo nodo
cheat.first = node;
guadagno = tempo[node];
}
if(node == radice) return cheat.second = guadagno; // se il nodo è una radice allora non ha fratelli, quindi la soluzione è guadagno
int father = parent[node];
if(adj[father].size() == 1) return cheat.second = guadagno; // vedi if con radice
int fratello = *next(adj[father].begin());
return cheat.second = min(guadagno, dp[node] - dp[fratello]); // se ha fratelli allora segue la logica che abbiamo usato con le foglie
}
void aggiorna(int node, ll val){ // aggiorniamo l'ordine del set
if(node == radice) { // se il nodo è la radice allora non esisterà nessun set da aggiornare
dp[node] = val;
return;
}
adj[parent[node]].erase(node); // eliminiamo il nodo in posizione vecchia
dp[node] = val; // aggiorniamo la dp
adj[parent[node]].insert(node); // mettiamolo in posizione nuova
}
void modifica(int node){ // funzione per modificare le dp dopo aver eliminato il nodo indivduato
if(adj[node].empty()) { // se è una foglia allora dp sarà 0
aggiorna(node, 0);
return modifica(parent[node]);
}
int figlio = *adj[node].begin();
aggiorna(node, dp[figlio] + tempo[node]); // se non è una foglia allora possiamo ricostruire la dp come con la dfs
if(node == radice) return; // se è la radice abbiamo finito
return modifica(parent[node]);
}
int main() {
fast();
int N, C; cin >> N >> C;
adj.resize(N, set<int, cmp>());
dp.resize(N, 0);
tempo.resize(N);
parent.resize(N);
for(int i = 0; i < N; ++i){
int a;
cin >> a >> tempo[i];
if(a == -1) { //radice
radice = i;
parent[radice] = -1;
continue;
}
adj[a].insert(i);
parent[i] = a;
}
if(N == 1){ // se N == 1 siamo in presenza di un caso particolare perchè solo in questo caso la radice non ha figli
if(C > 0) {
cout << 0 << endl;
}else{
cout << tempo[0] << endl;
}
return 0;
}
ll totale = dfs(radice); // dfs inizializza
dp[radice] = totale; // la dp della radice racchiude la soluzione con C = 0
for(int i = 0; i < N; ++i){ // aggiorniamo l'ordine dei set essendo che abbiamo modificato le dp
set<int, cmp> temp;
for(auto x : adj[i]){
temp.insert(x);
}
adj[i] = temp;
}
for(int i = 0; i < C; ++i){ // trattiamo il problema come se ci desse sempre C = 1 e ogni volta trovato il nodo da eliminare modifichiamo l'albero
totale = totale - individua(radice); // individua ritorna quanto risparmiamo eliminando il nodo migliore
tempo[cheat.first] = 0; // eliminiamo il nodo
modifica(cheat.first); // ricostruiamo le dp
}
cout << totale << endl;
return 0;
}
riscrivendo e aggiungendo i commenti per farvi capire meglio cosa fa, mi sono reso conto che usando i vector al posto dei set e sortandoli per aggiornarli sarebbe stata la stessa cosa e pure più facile a livello di implementazione, ma spero non sia questo il problema.
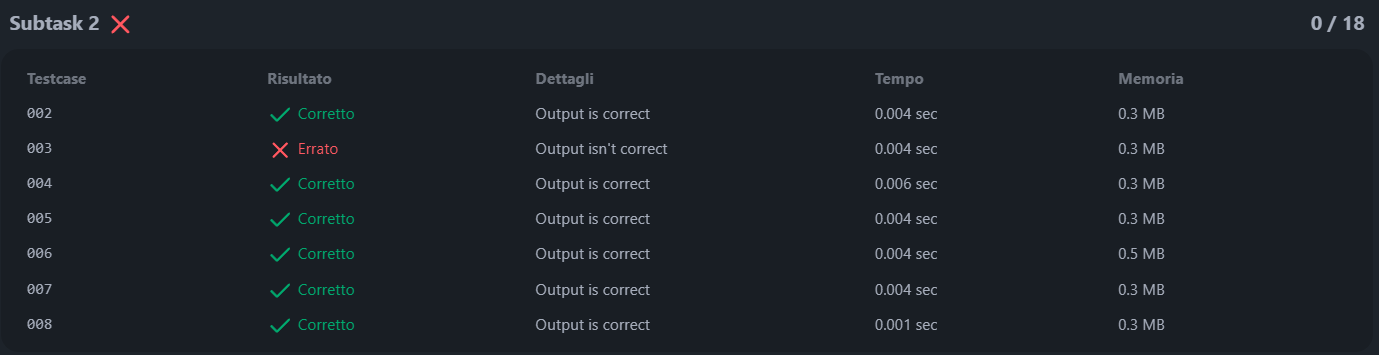
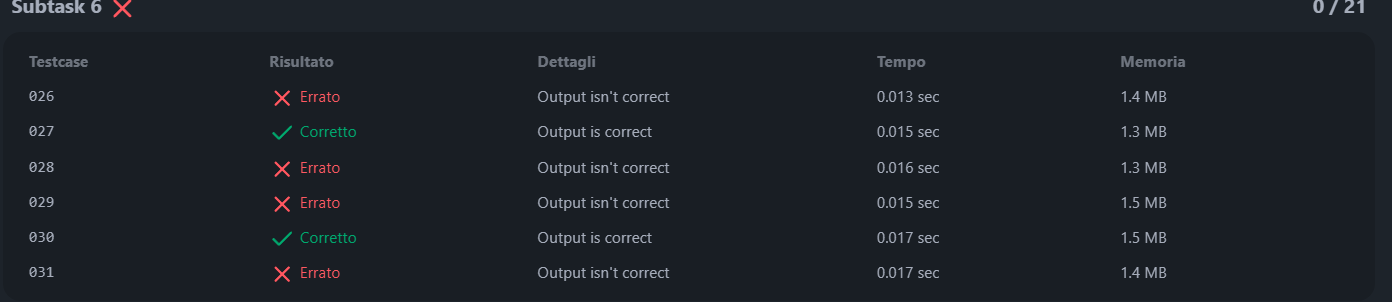
questi sono i testcase dove fallisco
Spero si capisca abbastanza, grazie in anticipo.