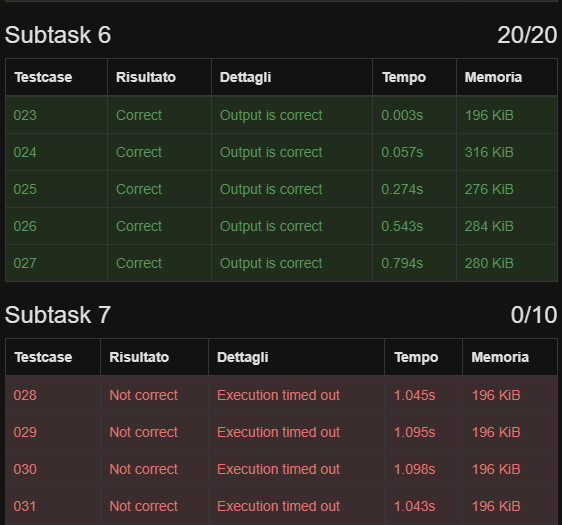
questo non riesce a fare gli ultimi testcase ovviamente per TLE, essendo che quando N > 50 000 000 l’algoritmo fa molta fatica visto che fa tante chiamate quanto è N
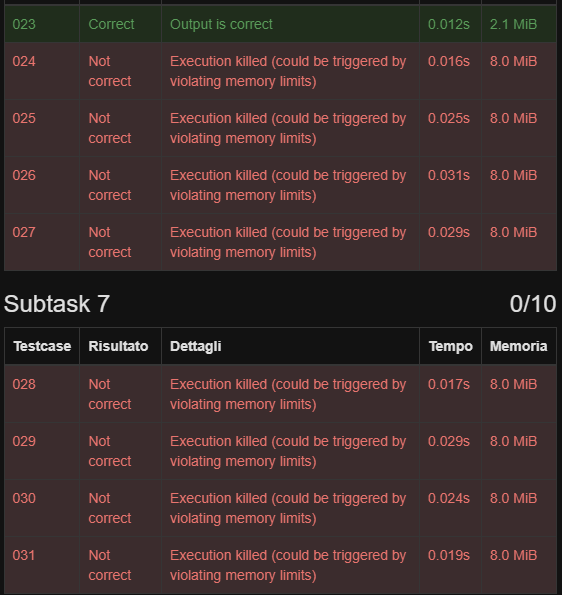
perchè il problema che fa 70/100 supera i limiti di memoria, e perchè anche avendo la stessa complessità del mio, è più veloce (mi viene da pensare che termina appena supera il limite e quindi non finisce tutte le chiamate però non so)
c’è necessariamente bisogno di una formula matematica generale? se si come devo ragionare per tirarla fuori o comunque per induzione generarla dai casi più piccoli?
è giusto spammare un pò ovunque i %mod? per stare sicuro li ho messi ovunque ma non so se possono essere un problema
Il tuo programma viene killato non appena raggiunge il limite di memoria.
Con un po’ di teoria sulle ricorrenze lineari puoi tirare un formula chiusa abbastanza brutta ma calcolabile in O(\log N), tuttavia per risolvere le ricorrenze lineari di solito si usa una tecnica particolare, cioè esponenziazione di matrici (trovi una spiegazione a pagina 220 della bibbia).
Sì i moduli vanno virtualmente ovunque se no rischi di overfloware.
grazie mille per l’aiuto, ci sono arrivato dopo un pò che bastava elevare la matrice per n, non hai idea dei video sulle successioni, matrici, autovalori, autovettori, stavo impazzendo, forse dovrei leggere meglio i consigli… Comunque sono soddisfatto di avercela fatta, alla fine conoscevo già la funzione di esponenziazione veloce, quindi mi è bastato capire come moltiplicare due matrici , essendo che in matematica non lo avevo mai fatto, ma implementarlo non è stato difficile… daje
questo è il codice giusto btw:
Di nulla. Visto che hai menzionato gli autovalori/autovettori descrivo anche una soluzione un po’ più complessa che ne fa uso (ma che, sottolineo, è abbastanza inutile).
Come hai visto il problema chiede di calcolare M^N con M=\begin{pmatrix}
3 & 2\\
3 & 3
\end{pmatrix}. Invece di calcolare direttamente questa quantità con esponenziazione veloce, possiamo per prima cosa “spostarci” nella base definita da due autovettori di M.
Lascio a te verificare che \begin{pmatrix}
2\\
\sqrt6
\end{pmatrix} e \begin{pmatrix}
2\\
-\sqrt6
\end{pmatrix} sono due autovettori linearmente indipendenti di M.
Possiamo allora trovare l’equivalente della nostra matrice nella nuova base calcolando M'=\begin{pmatrix}
2 & 2\\
\sqrt6 & -\sqrt6
\end{pmatrix}^{-1}\begin{pmatrix}
3 & 2\\
3 & 3
\end{pmatrix}\begin{pmatrix}
2 & 2\\
\sqrt6 & -\sqrt6
\end{pmatrix}=\begin{pmatrix}
3+\sqrt6 & 0\\
0 & 3-\sqrt6
\end{pmatrix}.
Come atteso, M' è diagonale e pertanto per elevarla all’N-esima potenza basta elevare singolarmente tutti gli elementi lungo la sua diagonale.
Abbiamo dunque trovato che (M')^N = \begin{pmatrix}
(3+\sqrt6)^N & 0\\
0 & (3-\sqrt6)^N
\end{pmatrix}, per ottenere la matrice M^N basta a questo punto invertire il cambio di base ottenendo:
\begin{align*}
M^N &= \begin{pmatrix}
2 & 2\\
\sqrt6 & -\sqrt6
\end{pmatrix} \begin{pmatrix}
(3+\sqrt6)^N & 0\\
0 & (3-\sqrt6)^N
\end{pmatrix}\begin{pmatrix}
2 & 2\\
\sqrt6 & -\sqrt6
\end{pmatrix}^{-1} \\
&=\begin{pmatrix}
\frac{1}{2}[(3+\sqrt6)^N + (3-\sqrt6)^N] & \frac{\sqrt6}{6}[(3+\sqrt6)^N - (3-\sqrt6)^N] \\
\frac{\sqrt6}{4}[(3+\sqrt6)^N - (3-\sqrt6)^N] & \frac{1}{2}[(3+\sqrt6)^N + (3-\sqrt6)^N]
\end{pmatrix}
\end{align*}
Ora basta implementare fastexp sui numeri della forma a+b\sqrt6 per calcolare in \mathcal{O}(\log N) le quantità richieste.
Lascio un esempio di implementazione:
#include <iostream>
using namespace std;
constexpr int MOD = 32749;
struct Num {
int a, b;
Num(int a, int b) : a(a), b(b) {}
Num operator*(const Num &o) const {
return Num((a * o.a + b * o.b % MOD * 6) % MOD, (a * o.b + o.a * b) % MOD);
}
};
Num fexp(Num b, int e) {
Num a(1, 0);
do {
if (e & 1) a = a * b;
b = b * b;
} while (e >>= 1);
return a;
}
int main() {
int N; cin >> N;
Num x = fexp(Num(3, 1), N);
Num y = fexp(Num(3, MOD - 1), N);
int A = (x.a + y.a) * ((MOD + 1) / 2) % MOD;
int B = 3LL * (x.b - y.b + MOD) * ((MOD + 1) / 2) % MOD;
cout << A << ' ' << B << '\n';
}