Normalmente ogni nodo contiene la propria chiave e, se necessario, un valore.
In un BST non bilanciato di N nodi l’altezza può essere proprio N - pensa al caso in cui vengono inseriti i valori già ordinati, quello che si forma è una lista, e ogni nodo ha solo un figlio invece di due.
In vasi quello che devi fare è supportare tre operazioni fondamentali: inserimento di un valore in una posizione, rimozione di un valore da una posizione, richiesta del valore in una posizione. Tutti e tre possono essere facilmente implementati con un avl, facendo attenzione a non utilizzare i valori come chiavi ma le dimensioni dei sottoalberi di ogni nodo.
Ci avevo pensato infatti, mi ero confuso nel tradurre: "After a long intermixed sequence of random insertion and deletion, the expected height of the tree approaches square root of the number of keys, √n, which grows much faster than log n"
Scusa ma non ti seguo, tralasciando l’implementazione che mi devo ancore vedere ( ), non riesco a capire quali sono gli elementi che deve contenere il mio BST tu parli di “dimensioni dei sottoalberi” ma non collego la cosa con il problema e poi, quale sarà la struttura iniziale dell’albero? E quali sono i valori che devo inserire per esempio"s 2 4"?
L’unica cosa che posso pensare è che la chiave sia quella detta da te, mentre il valore associato sia il vaso effettivo ma non ne sono sicuro
Quello che ti serve è una struttura dati che supporti le tre operazioni che ho detto prima. Questo perchè uno spostamento s a b è equivalente a eliminare il vaso in posizione a e inserirlo in posizione b, mentre c a è proprio la richiesta del valore salvato nella posizione a. Fin qui ci sei?
Pensa alla ricerca in un BST (per ora non importa se è bilanciato o meno, il funzionamento è identico, anche se ovviamente se non lo bilanci vai fuori tempo):
Il problema è che le chiavi sono in un certo senso implicite: non ci viene mai data una chiave univoca per ogni vaso, ma vengono indicizzati per posizione. Il problema con la posizione è che questa può cambiare con le varie operazioni, e quindi salvarla in ogni nodo non è possibile. Quello che possiamo fare è però mantenere per ogni nodo la dimensione del suo sottoalbero (che sarà 1 se il nodo non ha figli) e utilizzare questa per trovare l’$i$esimo elemento. Quindi quando siamo in un nodo r e stiamo cercando un elemento in posizione p lo avremo trovato se p == size(r->left), andremo a sinistra se p < size(r->left) o a destra se p > size(r->left).
Nella find() quindi, usando implicitamente la ricerca binaria dico, se il vaso che sto cercando è uguale a quello che sono ora(partendo dalla radice) restituisco la posizione del vaso (root->value) , se è maggiore vado al figlio destro se è minore a quello sinistro e ripeto il procedimento fino a quando trovo il valore desiderato.
Continuo a non capire , puoi provare con un esempio?
Quindi se un nodo n ha k sotto alberi vuol dire che è il kesimo +1valore più piccolo(?), altrimenti salgo o scendo nell’albero fino a quando si verifica quello detto in precedenza?
Perchè avendo k sottoalberi vuol dire che ha k valori più piccoli?
Scusate se riapro per la seconda volta il dead post ma sarei interessato anche io a risolvere vasi2, la mia domanda è come faccio a tenere bilanciato l’ albero se devo mantenere intatta l’ informazione della size (ovvero la somma delle altezze dei sottoalberi) ? non va ricalcolata per ogni nodo ogni volta che inserisco un’ elemento?
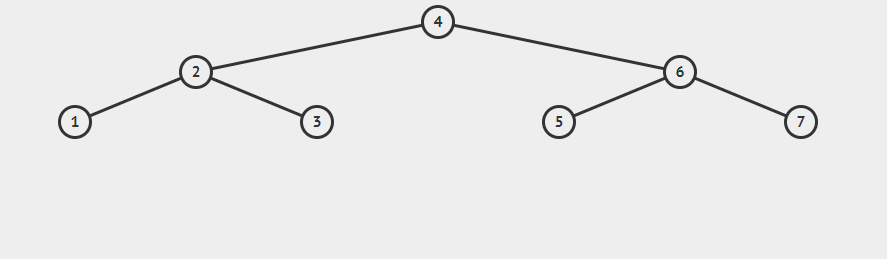
Se questo è l’ albero che rappresenta l’ array di partenza e voglio spostare il 2 in posizione 6 (1 3 4 5 2 6 7) allora elimino il 2 e lo reinserisco come successore di 5 facendolo diventare figlio destro di 5 ?
Scusate se riapro questa discussione dopo tanto tempo, ma mi e’ sorta una curiosita’: ho provato a risolvere vasi2 sia con treap che con avl e i treap prendono 40 per TLE. Capisco che i treap dovrebbero essere piu’ efficenti degli avl nel caso ci siano tante modifiche rispetto alle query. Considerato questo, qualcuno mi puo’ illustrare su quale potrebbe essere il bbst che performerebbe meglio in questo problema?
La ringrazio per la risposta immediata signor Borto.
In effetti questi dovrebbero avere una complessita’ migliore in questo problema, ma sembrano molto complicati, un’implementazione dei Y-fast potrebbe davvero migliorare i tempi in questo problema o le costanti sarebbero troppo alte?
Dopo averne discusso a lungo con @MyK_00L, abbiamo trovato un linguaggio di codifica che parrebbe essere una valida opzione per il tuo peculiar dilemma: Monicelli
 )
)